|
|
|
|
|


|
О проекте Что это Цель проекта Как это работает История версий Благодарности Частые вопросы |
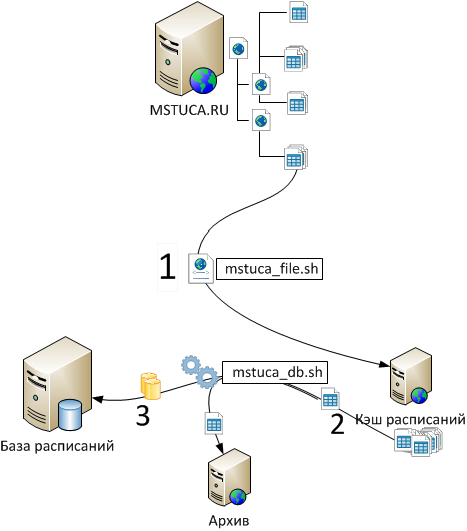
Как это работаетПроект работает на собственном мощным сервере, работающем под управлением ОС CentOS. Все расписания считываются автоматически из Excel-файлов, скачанных с официального источника. Самообновление расписанийСервер производит регулярные проверки файлов, расположенных на официальном источнике, и при появлении новых расписаний, сервер скачивает файлы в специальную папку. Скрипт-обработчик, выполняющий проверку и загрузку новых файлов расписаний помечен цифрой 1 на рисунке:
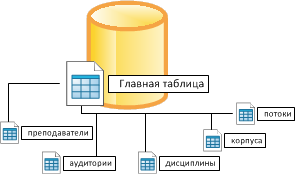
После успешной загрузки файлов в кэш, сервер производит проверку содержимого скачанных Excel-файлов. При успешной проверке, сервер производит считывание данных (2) в базу данных (3), при этом разделяя содержимое по подгруппам как по лабораторным работам, так и по группам иностранного языка ("начинающие" и "продолжающие" соответственно). Все данные (сами расписания, названия предметов, имена преподавателей, аудитории, корпуса, типы занятий и т.п.) хранятся раздельно для максимального обеспечения всеми возможностями и гибкости в обработке. Все расписания, принятые в базу данных, копируются в эту папку, при этом, каждый может загрузить выбранный Excel-файл непосредственно со страницы развёрнутого расписания. При обновлении расписаний, сервер производит регулярное резервирование старых расписаний путём упаковки всех Excel-файлов в архив, который доступен любому желающему. Как хранятся данные в базеБаза расписаний представляет из себя множество связных таблиц, объединённых главной таблицей. Главная таблица содержит в себе "занятия", прочитанные со страниц "неделя" и "подгруппы" оригинальных Excel-файлов. Каждое "занятие" привязывается ко дню недели, чётности недели, периоду проведения и конкретным дням проведения. В главной таблице присутствуют исключительно числовые данные: ID полей из связных таблиц, номер пары, день недели, чётность недели и даты проведения занятия.
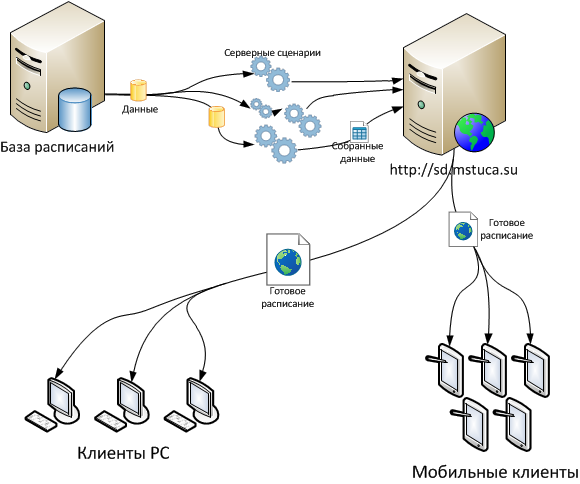
В связных таблицах хранятся все остальные данные: имена преподавателей, номера аудиторий, названия дисциплин, информация о студенческих потоках и т.п. Хранение данных в разных таблицах позволяет расширить спектр возможностей по использованию данных как в целом, так и различными частями. Вывод расписанийВсе данные из базы расписаний собираются и обрабатываются сценариями сервера приложений, после чего сформированная страница отправляется на веб-сервер, который передаёт её клиенту (компьютеру или смартфону/планшету пользователя):
Первый этап сбора данных - отбор данных по коду потока, группы, подгрупп (или по коду преподавателя) и по указанному дню или полное развёрнутое расписание. Вторым этапом идёт сбор данных из связных таблиц путём их объединения. Последний этап - формирование самого расписания и его вывод через Web-сервер на компьютер или мобильное устройство пользователя.
|